
국내 최초 인공지능(AI) 기반 한글 타자기록 문자인식 기술 개발-국가기록원, 인공지능 스타트업 기업과 연구개발 통해 이용자 접근성 확대
등록일 : 2020.12.22. 작성자 : 복원관리과






국내 최초 인공지능(AI) 기반 한글 타자기록 문자인식 기술 개발
- 국가기록원, 인공지능 스타트업 기업과 연구개발 통해 이용자 접근성 확대 -
□ 1960년대부터 1990년대까지 정부에서 주로 사용되었던 타자기록을 쉽고 간편하게 검색하고 활용할 수 있게 된다.
□ 국가기록원은 딥러닝 기반으로 약 22만 개의 한글 타자체 단어를 학습시켜 국내 최초로 비전자 타자기록의 인공지능(AI) 문자인식(OCR)* 기술 개발에 성공하였다고 밝혔다.
* 사람이 쓰거나 기계로 인쇄한 문자의 이미지를 기계가 읽을 수 있는 문자로 변환하는 기술
○ 이러한 기술은 국가기록원이 ‘20년 연구개발 사업의 일환으로 인공지능 스타트업 기업과 협업하여 수행한 「소장기록물 특성을 고려한 OCR 인식 성능 개선방안 연구」 과제를 통해 개발되었다.
□ 국가기록원은 그동안 문서를 이미지로 스캔한 파일을 제공해왔으나, 문서내용 검색에는 한계가 있어 이용자들의 불편이 있었다.
○ 특히 기존의 문자인식 기술은 활자체에 최적화되어 있어, 사람이 손으로 쓰거나 타자를 이용하여 작성된 문서의 경우에는 효과가 크지 않았다.
○ 타자기록은 1950년대에 최초로 세벌식 타자기가 양산되면서 정부의 공문서 작성에 쓰이기 시작했으며, 1969년에 네벌식, 1982년에 두벌식 자판이 사용되는 등 글꼴이 매우 다양하고 시각적으로 활자체와 차이가 있어 기존의 기술로는 인식성능이 떨어진다.
□ 이번 개발에 사용된 학습데이터는 1960~1990년대까지 재무부, 외무부, 건설교통부 등에서 생산한 도시계획, 경제계획 문서와 국무회의, 경제장관회의 등의 회의록 및 각종 법령 등을 대상으로 하고 있다.
○ 올해는 1단계로 공공기관에서 컴퓨터가 보급되기 이전에 주로 사용해 왔던 타자기록에 대해 문자인식 연구를 추진했다.
○ 그 결과, 기존의 문자인식 기술과는 달리 문자탐지와 문자인식의 2단계로 구성된 딥러닝 기반의 인공지능 문자인식 모델을 개발하여 학습 속도를 개선하고 인식성능을 90% 이상 획기적으로 높였다.
□ 앞으로 국가기록원은 문자인식 기술을 적용·발전시켜 국민들이 보다 쉽고 편리하게 기록물을 활용할 수 있도록 비전자 기록물의 원문 검색 및 색인 등의 정보 활용 서비스에 확대 적용할 계획이다.
○ 아울러, 이번에 구축된 학습데이터는 국가기록원 누리집을 통해 공개될 예정이다.
(예시) 1973년 외무부 기안문, 문자인식 전·후 비교표
문자인식 전 문자인식 후
□ 안경원 국가기록원장 직무대리는 “이번 연구를 통해 개발된 기술은 국가기록원의 기록물 접근성 향상에 기여했다는 점에서 큰 의미가 있다.”며 “국가기록원은 앞으로도 인공지능 기술 등의 접목을 통해 국민들이 필요한 서비스를 제공할 수 있도록 노력하겠다.”라고 밝혔다.
참고1 한글 타자기록 문자인식 기술 개발 추진개요
□ 추진배경
○ 국가기록원은 정부 부처에서 주로 1960~1990년대까지, 약 40년 동안 생산한 타자기록 11만권* 이상 보유
* 1960년대 1.9만권, 1970년대 3.9만권, 1980년대 2.8만권, 1990년대 2.7만권 보유
○ 타자기록은 활자체에 최적화된 기존 문자인식* 기술의 한계로 단어 검색이 안되는 스캔 이미지로 제공되는 등 문자인식 성능개선 필요
* 문자인식(Optical Character Recognition, OCR) : 사람이 쓰거나 기계로 인쇄한 문자의 이미지를 기계가 읽을 수 있는 문자로 변환하는 기술
□ 추진 내용
○ (인식대상) 1960~1980년대 재무부, 외무부, 건설교통부 등에서 생산한 타자기록 1,970장 (전체 22만 단어)
○ (인식방법) 데이터 수집 → 데이터 라벨링 → 텍스트 전사 → OCR모델 학습
① 데이터 수집 : 타자기록의 스캔 이미지 선별
* 생산년도·생산기관 등 다양하게 포함
② 데이터 라벨링 : 인식대상 기록물의 각 단어를 감싸는 바운딩박스 생성
③ 텍스트 전사 : 작업자가 각 바운딩박스 내 텍스트 값 입력
④ OCR모델 학습 : 딥러닝 기반으로 22만 단어를 학습시켜 OCR모델 인식성능 개선
데이터 수집 데이터 라벨링 텍스트 전사 OCR모델 학습
○ (주요기록물) 정책문서, 회의록, 각종 법령·규정·조례 등 포함
주요 유형 주요내용
① 정책문서 대통령지시시항(행자부, 1967), 제5차 경제개발5개년계획(건설부, 1978), 서울도시계획(건설부, 1978), 대통령취임식계획(총무처, 1979), 지자체 실시방향(행자부, 1986) 등
② 회의록 국무회의안건철(총무처, 1977), 경제장관회의안건(경제기획원, 1969), 중앙도시계획위원회 회의록(건설부, 1974), 외자사업투자심사위원회(재무부, 1977) 등
③ 법령 등 지방세조례(행자부, 1973), 예규(대검찰청, 1975), 도시계획시설기준개정(건설교통부, 1979), 조례원본(경기도, 1980), 지방자치법 법제처심사(행자부, 1986) 등
④ 외교문서 UN 특별총회(1967), 분단국가 UN 동시가입 문제(외무부, 1970), 한일각료회의(재무부, 1972), WHO 총회(외무부, 1973), 국가간협정(농촌진흥청, 1977), 한일민간경협합동회의(재무부, 1977),
한싱가폴조세협약(재무부, 1978) 등
□ 기술개발 의의와 효과
○ 비전자 기록물을 디지털 파일로 변환한 후 문자인식 기술을 적용함으로써 기록물의 검색과 활용도를 높일 수 있을 것으로 기대
○ 디지털 파일로부터 텍스트를 추출하는 작업을 수작업으로 할 경우 많은 시간과 비용이 들게 되나, 개발기술 적용으로 특정 단어를 검색하여 비전자 기록물 내에서 그 단어가 있는 위치를 자동으로 찾고 원하는 내용을 빠르게 검색 가능
□ 향후계획
○ 내년부터 모든 비전자 기록물을 데이터화하는 ’기록물 디지털화 2.0 계획‘ 추진 예정
참고2 타자기록 문자인식 기술 주요내용
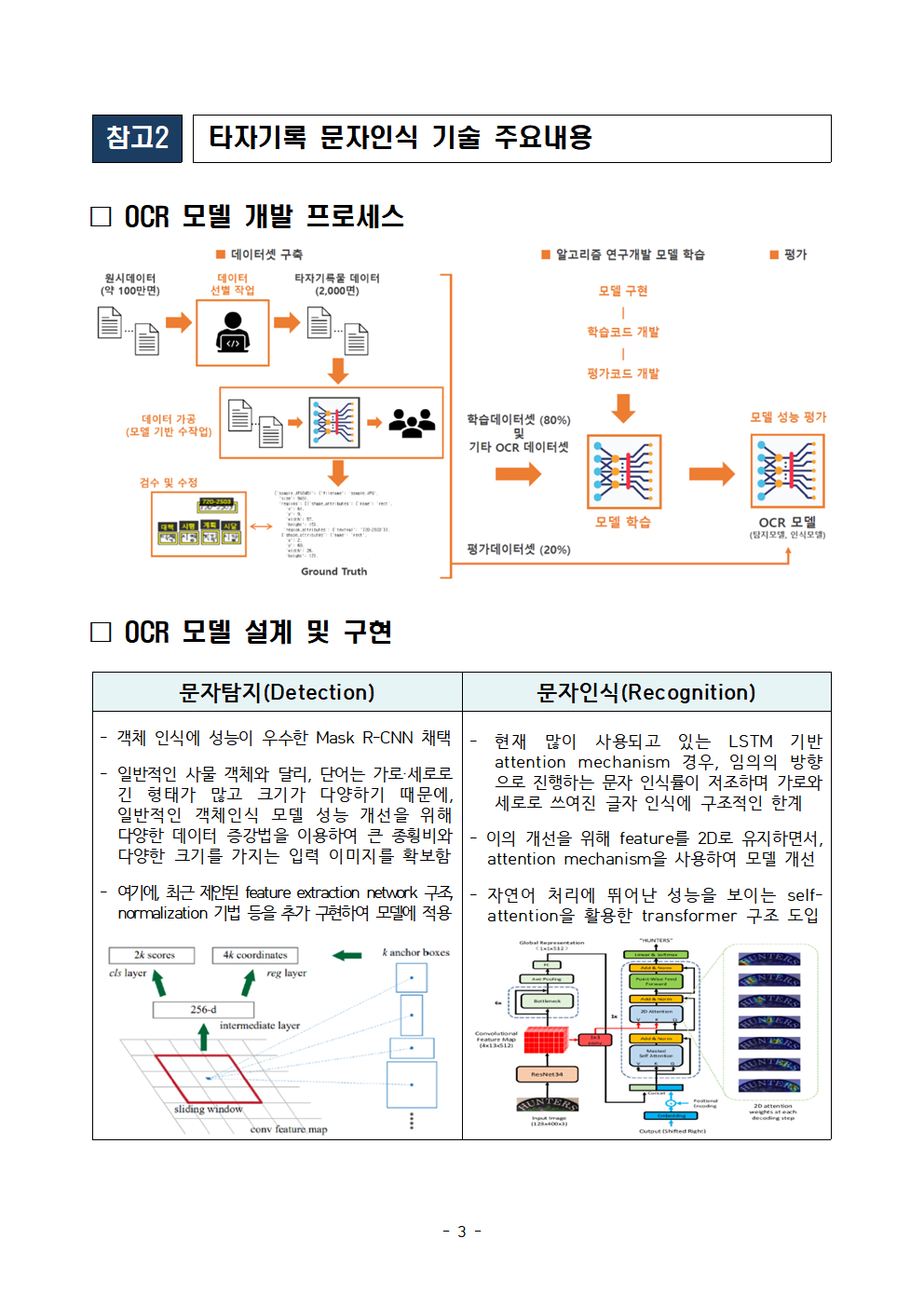
□ OCR 모델 개발 프로세스
□ OCR 모델 설계 및 구현
문자탐지(Detection) 문자인식(Recognition)
- 객체 인식에 성능이 우수한 Mask R-CNN 채택 - 현재 많이 사용되고 있는 LSTM 기반 attention mechanism 경우, 임의의 방향으로 진행하는 문자 인식률이 저조하며 가로와 세로로 쓰여진 글자 인식에 구조적인 한계
- 일반적인 사물 객체와 달리, 단어는 가로·세로로 긴 형태가 많고 크기가 다양하기 때문에, 일반적인 객체인식 모델 성능 개선을 위해 다양한 데이터 증강법을 이용하여 큰 종횡비와 다양한 크기를 가지는 입력 이미지를 확보함 - 이의 개선을 위해 feature를 2D로 유지하면서, attention mechanism을 사용하여 모델 개선
- 여기에, 최근 제안된 feature extraction network 구조, normalization 기법 등을 추가 구현하여 모델에 적용 - 자연어 처리에 뛰어난 성능을 보이는 self- attention을 활용한 transformer 구조 도입
참고3 타자기록 문자인식 주요 사례
구분
타자
인식
표형식
영문
인식
강조선
'판교핫뉴스1' 카테고리의 다른 글
| 65세 이후에도 장애인 활동지원 서비스를 받을 수 있습니다. (0) | 2020.12.22 |
|---|---|
| 코로나바이러스감염증-19 국내 발생 현황 (2020-12-22, 정례브리핑) (0) | 2020.12.22 |
| 대리점법 일부개정안 국무회의 통과-단체구성권・동의의결제도 도입 등 대리점의 협상력 및 피해구제 강화 (0) | 2020.12.22 |
| 온라인쇼핑몰업자의 불공정행위 심사지침 제정(안) 행정예고 (0) | 2020.12.22 |
| 여신전문금융업법 시행령 개정안 국무회의 의결-카드사가 법인회원에게 과도한 경제적 이익을 제공하지 못하도록 하는 등 제도개선을 하였습니다.담당부서: 중소금융과 (0) | 2020.12.22 |